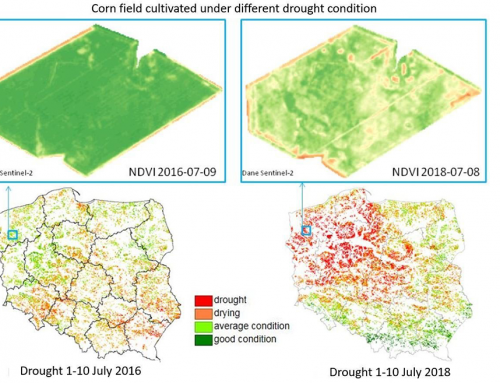
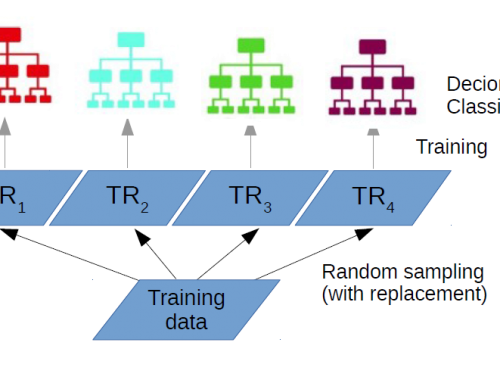
Product Description
D ecision Trees (DT) is a non-parametric classifier that gained popularity in different domains because its structure is explicit and easily interpretable.
A DT is built by recursively splitting each tree node using a statistical procedure such as Gini impurity measure, information gain (for classification scenarios), or variance (for prediction problems).
In this lecture, we will be introducing the main steps required for building a DT. Two procedures used to select the best variables for splitting the tree nodes will be discussed by making use of a practical example. These procedures include Gini impurity and information gain. The overfitting and underfitting concepts will be explained in the second part of the lecture when we will introduce two solutions to build the optimal DT, i.e. a DT that does not overfit: (1) stop growing the DT early before overfitting and (2)pruning or reducing the size of the tree.
The lecture ends up by listing the main advantages and disadvantages of DT.
Learning outcomes
Explain how information gain and Gini impurity is calculated.
Present the main advantages and disadvantages of decision trees classifier.
Describe the concept of over-fitting and under-fitting.
Define the main solutions that can be applied to avoid decision trees over-fitting.

BoK concepts
Links to concepts from the EO4GEO Body of Knowledge used in this course:
-
- > AM | Analytical Methods
- > AM10 | Data mining
- > AM10-2 | Data mining approaches
- > AM10 | Data mining
- > IP | Image processing and analysis
- > IP3 | Image understanding
- > IP3-4 | Image classification
- > IP3-4-5 | Decision trees
- > IP3-4-7 | Machine learning
- > IP3-4-9 | Sampling strategies
- > IP3-4 | Image classification
- > IP3 | Image understanding
- > AM | Analytical Methods
Material preview
Ownership
Designed and developed by: Mariana Belgiu, University of Twente.
License: Creative Commons Attribution-ShareAlike.
Education level
EQF 6 (what is this?)
Language
![]() English
English
Creation date
2020-06-20
Access
Find below a direct link to the HTML presentation.
Find below a link to the GitHub repository where you can download the presentation.